加密货币交易所十一:持仓管理

持仓管理是合约交易所系统的核心功能之一,它直接关系到用户的交易体验、风险控制和系统的整体稳定性。本章将详细探讨持仓管理的各个方面,包括持仓数据模型、全仓和逐仓的区别、持仓盈亏实时计算以及持仓量统计和限制。
11.1 持仓数据模型
持仓数据模型是整个持仓管理系统的基础,它定义了如何存储和管理用户的持仓信息。
11.1.1 核心数据结构
一个典型的持仓数据模型通常包含以下字段:
- 用户ID:唯一标识持仓所属的用户
- 合约ID:标识具体的交易合约
- 持仓方向:多头(Long)或空头(Short)
- 持仓数量:当前持有的合约数量
- 开仓均价:建立该持仓的平均价格
- 杠杆倍数:该持仓使用的杠杆倍数
- 已实现盈亏:已经平仓部分的盈亏
- 未实现盈亏:当前持仓的浮动盈亏
- 保证金:该持仓占用的保证金
- 仓位模式:全仓或逐仓
- 时间戳:最后更新时间
11.1.2 数据模型设计考虑
性能优化:
- 使用列式存储(如Apache Parquet)优化大量持仓数据的读取性能
- 对频繁访问的字段(如持仓数量、未实现盈亏)建立索引
一致性:
- 使用乐观锁或悲观锁确保并发更新的一致性
- 实现事务机制,保证相关操作的原子性(如开仓同时扣除保证金)
可扩展性:
- 设计支持分片的数据模型,便于未来按用户ID或合约ID进行水平扩展
- 考虑使用NoSQL数据库(如Cassandra)以支持更灵活的模式演进
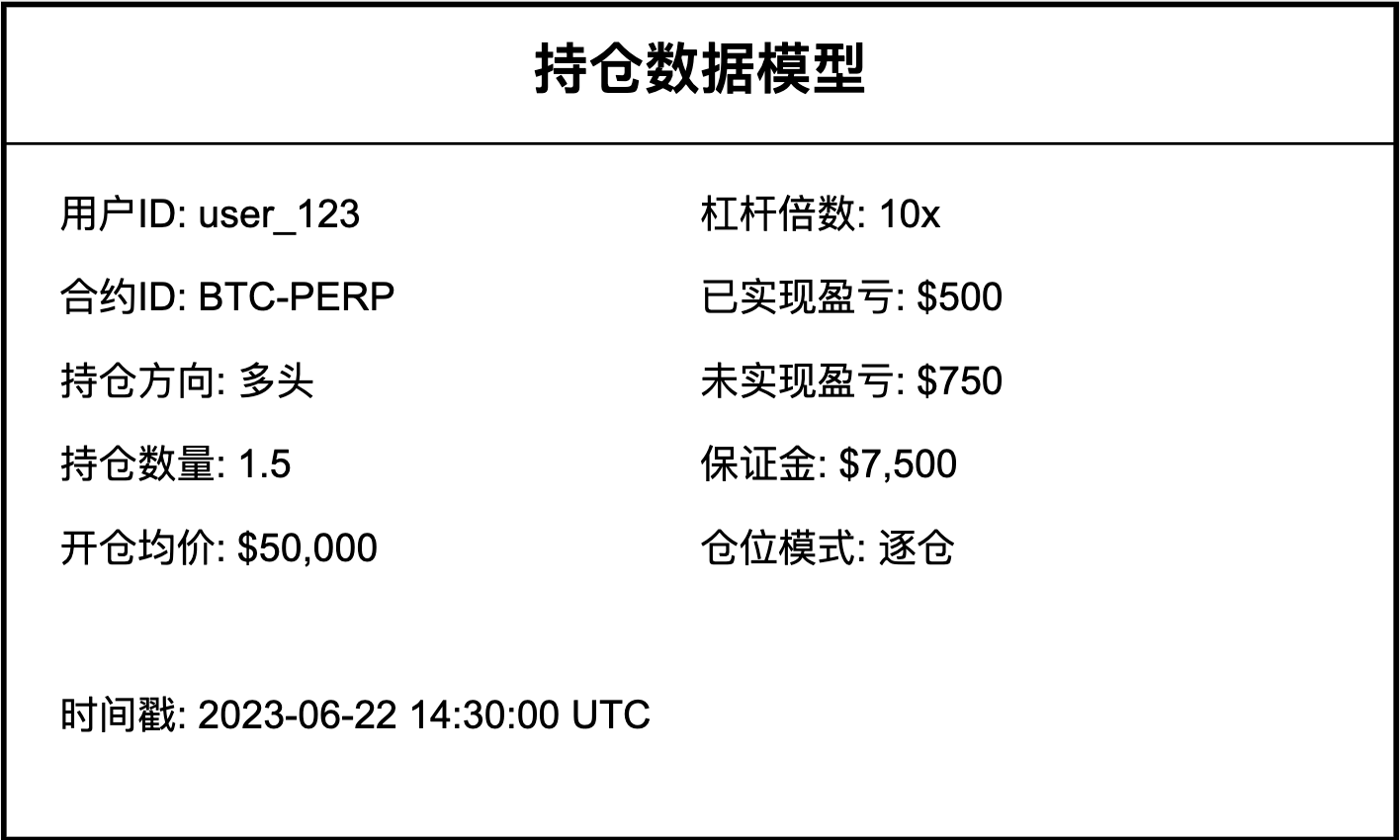
这个图表展示了一个典型的持仓数据模型的结构,包含了关键字段及其示例值。
11.2 全仓和逐仓持仓的区别
全仓和逐仓是两种不同的保证金模式,它们在风险管理和资金利用效率方面有显著差异。
11.2.1 全仓模式(Cross Margin)
在全仓模式下,用户的所有持仓共享同一个保证金池。
特点:
- 更高的资金利用率
- 较低的强制平仓风险
- 不同合约之间的盈亏可以相互抵消
实现考虑:
- 需要实时计算整个账户的风险率
- 平仓操作需要考虑所有持仓的综合情况
- 保证金不足时,需要实现优先平仓策略(如按风险贡献排序)
11.2.2 逐仓模式(Isolated Margin)
逐仓模式下,每个持仓都有独立的保证金账户。
特点:
- 风险隔离,一个持仓的亏损不会影响其他持仓
- 用户可以更精细地控制每个持仓的风险
- 强制平仓时只影响单个持仓
实现考虑:
- 需要为每个持仓单独维护保证金账户
- 平仓操作相对简单,只需考虑单个持仓的情况
- 可以实现更灵活的保证金调整策略
11.2.3 模式对比
| 特性 | 全仓模式 | 逐仓模式 |
|---|---|---|
| 资金效率 | 高 | 低 |
| 风险隔离 | 低 | 高 |
| 管理复杂度 | 高 | 低 |
| 适用人群 | 经验丰富的交易者 | 风险厌恶型交易者 |
11.2.4 实现策略
- 数据模型:
- 全仓:在用户级别维护一个总保证金字段
- 逐仓:在每个持仓记录中维护独立的保证金字段
- 风险计算:
- 全仓:综合计算所有持仓的风险
- 逐仓:单独计算每个持仓的风险
- 保证金调整:
- 全仓:实现从总保证金池分配和回收资金的机制
- 逐仓:允许用户直接调整单个持仓的保证金
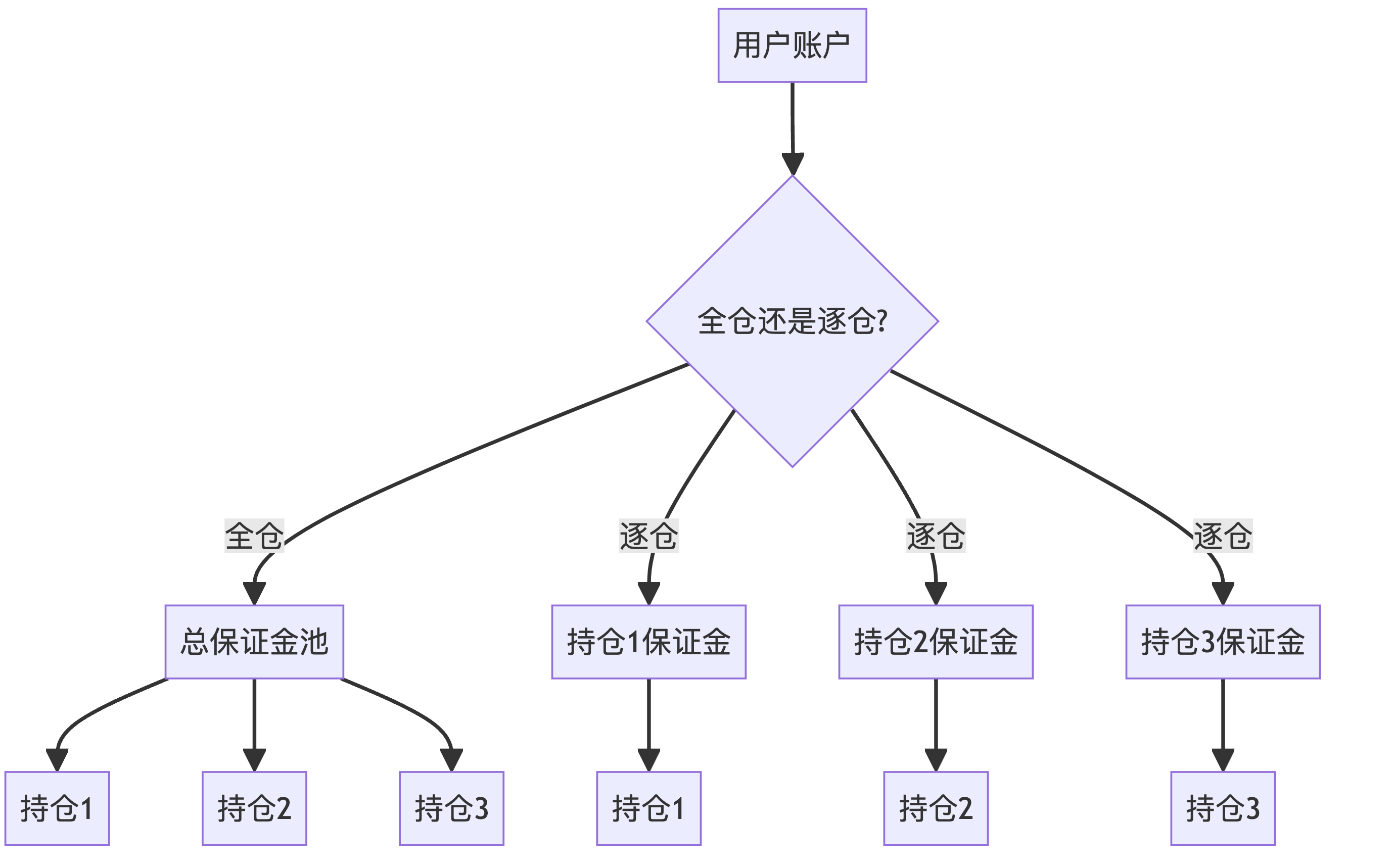
这个流程图展示了全仓和逐仓模式下资金分配的不同。在全仓模式下,所有持仓共享一个保证金池;而在逐仓模式下,每个持仓都有自己独立的保证金。
11.3 持仓盈亏实时计算方法
实时计算持仓盈亏是交易系统的关键功能,它直接影响用户的交易决策和风险管理。
11.3.1 未实现盈亏计算
未实现盈亏(Unrealized PNL)是指当前持仓的浮动盈亏,计算公式如下:
对于多头持仓:
未实现盈亏 = (当前市价 - 开仓均价) * 持仓数量
对于空头持仓:
未实现盈亏 = (开仓均价 - 当前市价) * 持仓数量
11.3.2 已实现盈亏计算
已实现盈亏(Realized PNL)是指已经平仓部分的盈亏,计算公式如下:
已实现盈亏 = 平仓收入 - 开仓成本
其中,平仓收入和开仓成本需要考虑交易手续费。
11.3.3 实时计算的挑战和解决方案
高频更新:
- 挑战:市场价格频繁变动导致持续的计算压力
- 解决方案:使用增量计算方法,只计算价格变化带来的差额
大规模并发:
- 挑战:大量用户同时持仓,需要并发计算
- 解决方案:使用分布式计算框架(如Apache Flink)进行实时流处理
数据一致性:
- 挑战:确保盈亏计算与其他系统(如风控、清算)的数据一致
- 解决方案:实现事件溯源(Event Sourcing)模式,保证数据的一致性和可追溯性
性能优化:
- 挑战:需要在毫秒级别完成大量持仓的盈亏计算
- 解决方案:使用内存数据网格(如Hazelcast)存储热点数据,加速计算
11.3.4 实现策略
数据缓存:
- 使用分布式缓存(如Redis)存储最新的市场价格和用户持仓信息
- 实现订阅-发布机制,确保价格更新能快速传播到计算模块
异步计算:
- 使用消息队列(如Kafka)缓冲需要计算的持仓更新事件
- 部署专门的计算工作节点处理这些事件,更新盈亏结果
批量处理:
- 实现微批处理机制,在毫秒级时间窗口内聚合多个更新,一次性计算
- 使用向量化计算技术(如SIMD指令)加速批量计算
近似计算:
- 对于非关键场景,可以考虑使用近似计算方法
- 例如,使用指数移动平均(EMA)来平滑市场价格波动,减少计算频率
11.4 持仓量统计和限制
持仓量统计和限制是风险管理的重要组成部分,它们帮助交易所控制市场风险和个人风险。
11.4.1 持仓量统计
持仓量统计包括个人持仓量和全市场持仓量的计算和更新。
关键指标:
- 总持仓量:所有用户的持仓总和
- 净持仓量:多头总量减去空头总量
- 持仓集中度:top N个用户的持仓量占总持仓量的比例
实现考虑:
- 使用增量更新方法,避免频繁的全量计算
- 实现多级缓存策略,加速查询性能
- 采用时间序列数据库(如InfluxDB)存储历史持仓量数据,支持趋势分析
11.4.2 持仓限制
持仓限制是控制风险的重要手段,包括个人限制和市场限制。
限制类型:
- 个人最大持仓量:单个用户的最大允许持仓量
- 市场最大持仓量:整个市场的最大允许持仓量
- 持仓集中度限制:防止单个或少数用户控制过多市场份额
实现策略:
- 在下单时进行预检查,拒绝超出限制的订单
- 实现动态调整机制,根据市场条件自动调整限制
- 设置预警阈值,在接近限制时发出警告
11.4.3 实时监控和预警系统
实时监控和预警系统是有效执行持仓量统计和限制的关键组成部分。它能够及时发现潜在风险,并触发相应的风控措施。
主要功能:
- 实时数据采集:
- 从交易引擎和清算系统实时获取持仓变动数据
- 使用高性能消息队列(如Apache Kafka)传输数据
- 持续计算:
- 使用流处理框架(如Apache Flink或Spark Streaming)进行实时计算
- 维护滑动窗口统计,如5分钟、1小时、24小时的持仓量变化
- 阈值监控:
- 设置多级阈值,如警告级、危险级、紧急级
- 对不同级别的阈值设置不同的监控频率和响应策略
- 智能预警:
- 利用机器学习算法预测持仓量趋势
- 基于历史数据和当前市场情况动态调整预警阈值
- 多维度分析:
- 按合约、用户类型、地理位置等多个维度进行持仓分析
- 识别异常模式,如突然的大额持仓增加或减少
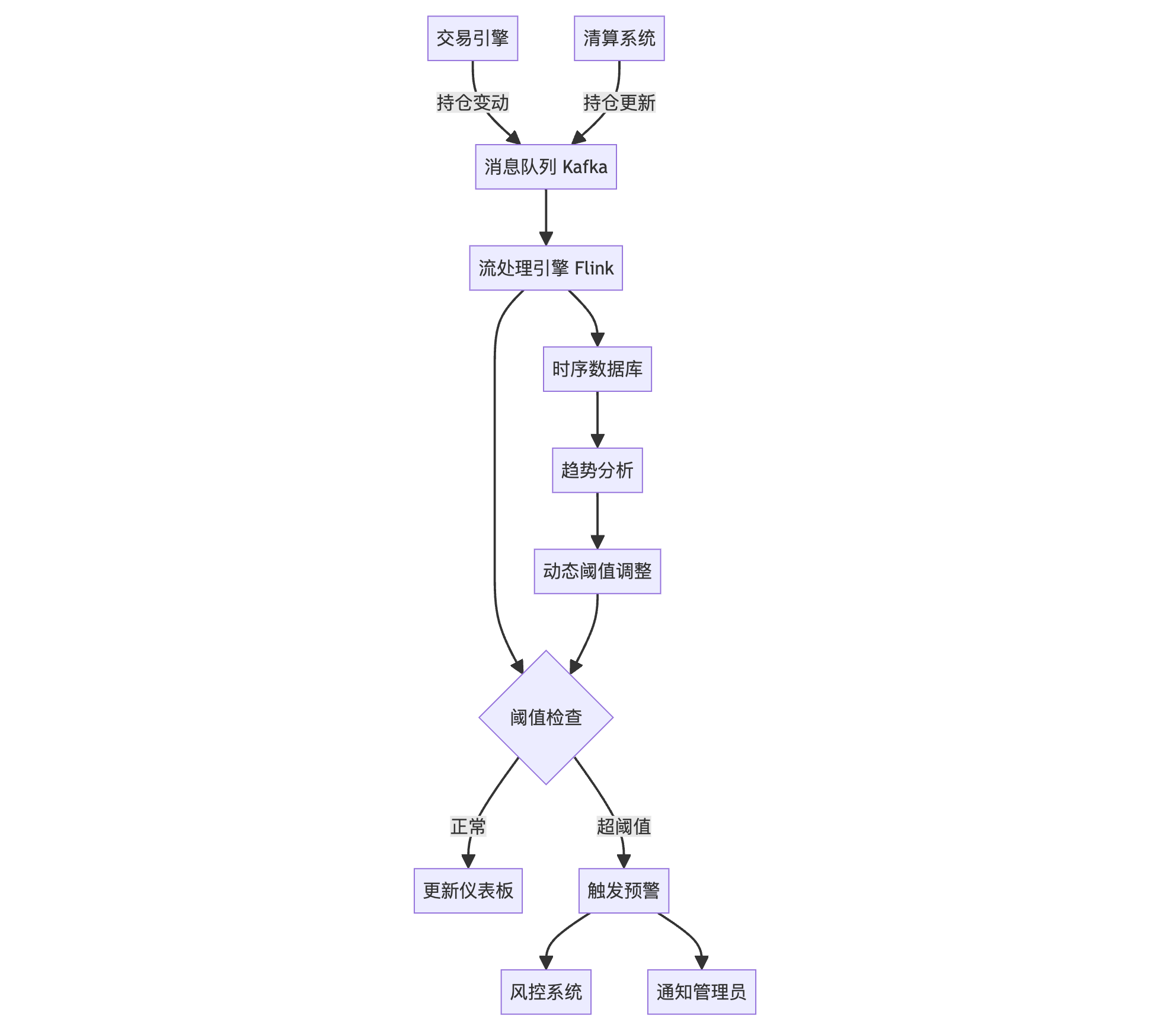
这个流程图展示了从数据采集到预警触发的整个过程,包括实时处理、阈值检查、预警触发以及动态阈值调整的反馈循环。
11.4.4 实现最佳实践
- 分层架构:
- 数据采集层:高性能、低延迟的数据收集
- 计算层:分布式流处理,支持横向扩展
- 存储层:合理使用内存数据库和持久化存储
- 展示层:实时更新的可视化仪表板
- 性能优化:
- 使用本地缓存减少网络请求
- 实现批处理机制,平衡实时性和系统负载
- 使用异步处理,分离关键路径和非关键操作
- 可靠性保证:
- 实现数据校验机制,确保数据一致性
- 设计降级策略,在极端情况下保证核心功能
- 建立完整的日志和审计跟踪系统
- 可扩展性设计:
- 使用微服务架构,便于独立扩展各个组件
- 实现动态分片策略,支持水平扩展
- 采用云原生技术,如容器化和服务网格
- 智能化:
- 集成机器学习模型,预测持仓趋势
- 实现异常检测算法,自动识别可疑的持仓模式
- 使用自适应算法动态调整监控参数
11.5 案例研究:BitMEX的持仓管理系统
BitMEX作为一个领先的加密货币衍生品交易平台,其持仓管理系统值得研究。
关键特性:
- 高性能持仓更新:
- 使用内存数据网格技术,实现毫秒级的持仓更新
- 报告的峰值性能:每秒处理超过30万次持仓更新
- 风险管理:
- 实现自动减仓(Auto-Deleveraging)机制,在极端市场条件下管理风险
- 使用公平价格标记机制,防止价格操纵导致的不合理强平
- 灵活的保证金系统:
- 支持全仓和逐仓模式,允许用户灵活选择风险策略
- 实现动态保证金要求,根据市场波动性调整保证金比例
- 实时透明度:
- 提供实时的持仓量和资金费率数据,增加市场透明度
- 公开大户持仓排行榜,让用户了解市场结构
- 创新功能:
- 推出永续合约,结合了现货和期货的特点
- 实现复杂的条件单类型,如跟踪止损单
性能数据:
- 平均持仓更新延迟:<10ms
- 日均持仓数量:超过100万个
- 系统可用性:99.999%
通过这些创新和高性能的持仓管理系统,BitMEX在竞争激烈的加密货币衍生品市场中保持了领先地位。
总结
持仓管理是合约交易所的核心功能之一,它涉及复杂的数据模型设计、实时计算、风险控制和性能优化。通过实施全面的持仓数据模型、灵活的保证金模式、高效的盈亏计算方法以及严格的持仓限制和监控系统,交易所可以为用户提供安全、高效的交易环境。
未来的持仓管理系统将更加智能化、去中心化,并且更注重隐私保护和跨链操作。这些趋势将推动交易所不断创新,以满足日益复杂的市场需求和监管要求。
对于开发者来说,构建一个高性能、可靠的持仓管理系统需要深入理解金融模型、分布式系统和实时计算技术。持续的性能优化、创新的风险管理策略以及对新技术的探索将是保持竞争力的关键。
