加密货币交易所五:交易引擎

交易引擎是合约交易所的核心组件,负责处理订单匹配、执行交易和维护订单簿。它的性能、可靠性和公平性直接影响整个交易所的运作效率和用户体验。本章将详细探讨交易引擎的各个方面,包括订单类型支持、撮合算法实现、订单簿管理以及高频交易支持。
订单类型支持
合约交易所通常支持多种订单类型,以满足不同交易者的需求。每种订单类型都有其特定的处理逻辑和优先级。
主要订单类型
市价单(Market Order)
- 概念:以当前最优价格立即成交的订单。
- 特点:保证成交,但不保证价格。
- 处理逻辑:立即与订单簿中的对手方订单匹配,直到完全成交或耗尽可用流动性。
限价单(Limit Order)
- 概念:指定价格的买入或卖出订单。
- 特点:保证价格,但不保证成交。
- 处理逻辑:如果可以立即成交,则成交;否则加入订单簿等待匹配。
止损单(Stop Loss Order)
- 概念:当市场价格达到指定的触发价格时,自动转为市价单。
- 特点:用于限制损失或锁定利润。
- 处理逻辑:监控市场价格,触发后转为市价单处理。
止盈单(Take Profit Order)
- 概念:当市场价格达到指定的获利价格时,自动转为市价单。
- 特点:用于自动实现既定利润目标。
- 处理逻辑:类似止损单,但通常用于相反的价格方向。
冰山订单(Iceberg Order)
- 概念:大额订单被拆分成多个小额订单,只显示一小部分。
- 特点:隐藏大单,减少市场冲击。
- 处理逻辑:显示部分作为普通限价单处理,成交后自动补充显示量。
跟踪止损单(Trailing Stop Order)
- 概念:止损价格随市场价格变动而调整的止损单。
- 特点:可以在保护利润的同时让利润继续增长。
- 处理逻辑:持续更新触发价格,一旦触发则转为市价单。
订单生命周期管理
订单从创建到最终状态经历多个阶段,交易引擎需要精确管理每个阶段的状态变化。
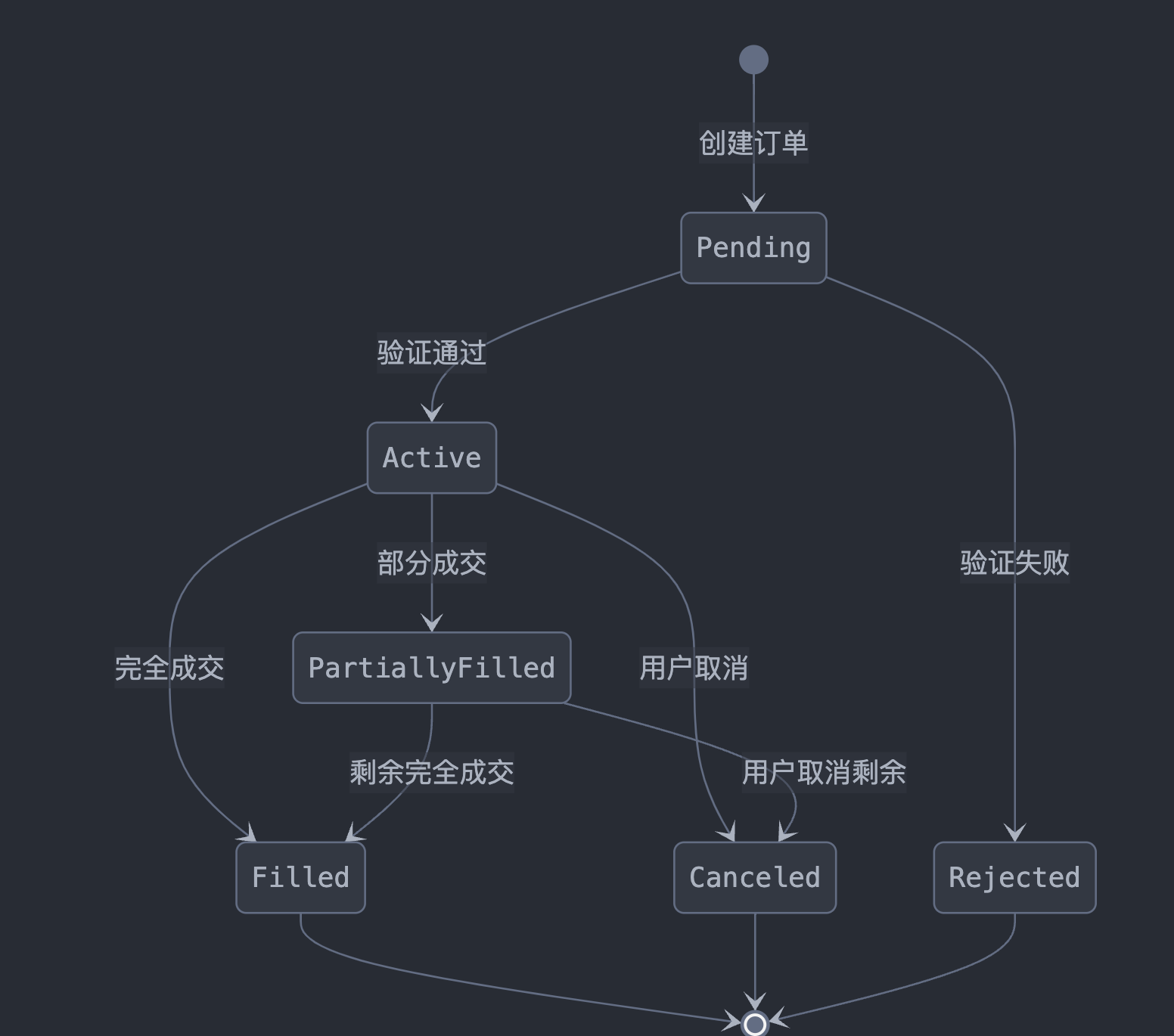
这个状态图展示了订单从创建到最终状态的完整生命周期,包括pending(待处理)、active(活跃)、partially filled(部分成交)、filled(完全成交)、canceled(已取消)和rejected(被拒绝)等状态。
订单状态管理的关键点:
- 原子性:状态转换必须是原子操作,避免出现不一致状态。
- 持久化:每次状态变更都需要持久化,以支持故障恢复。
- 事件驱动:使用事件驱动架构,在状态变更时触发相应的操作(如通知用户)。
- 幂等性:确保重复操作不会导致错误结果,支持故障重试。
撮合算法实现
撮合算法是交易引擎的核心,它决定了订单如何匹配和成交。高效的撮合算法直接影响交易所的性能和公平性。
价格优先、时间优先(Price-Time Priority)
这是最常用的撮合算法,也称为"先价格后时间"(FIFO)算法。
原理:
- 首先按照价格优先级排序(买单降序,卖单升序)。
- 价格相同时,按照订单进入系统的时间先后排序。
实现考虑:
- 使用优先队列(如红黑树)维护订单,支持快速插入和删除。
- 对于每个价格级别,使用队列存储同价格的订单。
性能优化:
- 预先分配内存,避免动态内存分配。
- 使用无锁算法处理并发操作,提高吞吐量。
Pro-rata撮合算法
在一些衍生品交易所中使用,按比例分配成交量。
原理:
- 找到可以成交的最优价格。
- 按照每个订单的数量比例分配成交量。
计算公式: 分配给订单A的成交量 = (订单A的数量 / 该价格级别的总订单数量) * 可成交的总量
优缺点:
- 优点:有利于大额订单,增加市场流动性。
- 缺点:实现复杂,可能导致频繁的小额部分成交。
混合算法
一些交易所采用价格优先、时间优先和Pro-rata的混合算法。
示例:
- 80%的成交量按Pro-rata分配。
- 20%的成交量按时间优先分配。
- 设置最小成交量阈值,避免过小的成交。
订单簿管理
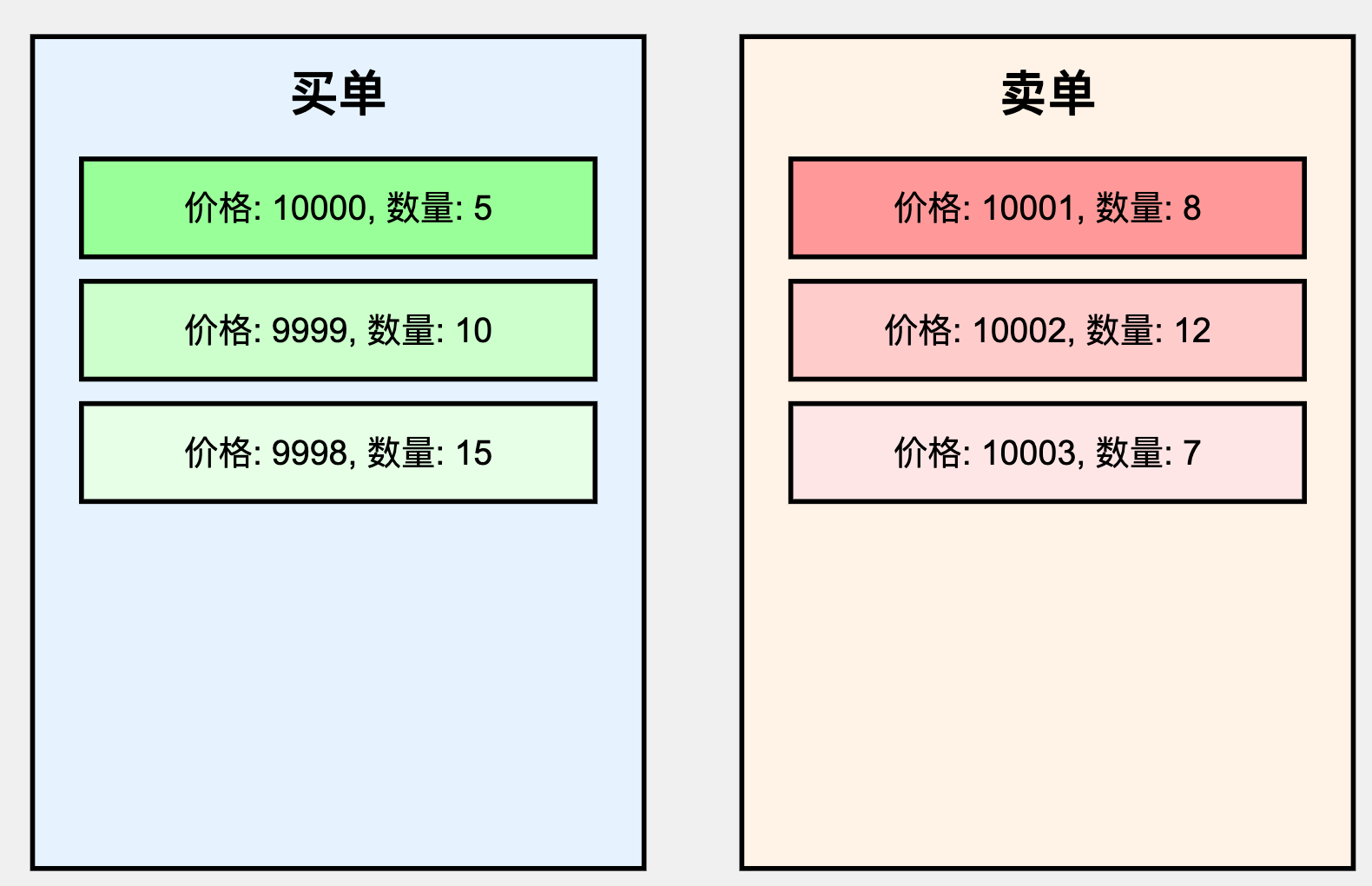
订单簿是撮合引擎的核心数据结构,它维护了当前市场上所有未成交订单的状态。
数据结构
典型实现:
- 使用两个优先队列,分别存储买单和卖单。
- 每个价格级别维护一个订单链表。
性能优化
- 内存管理:使用内存池预分配订单对象,减少动态内存分配。
- 缓存友好:优化数据结构布局,提高缓存命中率。
- 并发控制:使用细粒度锁或无锁算法,提高并发处理能力。
- 批量处理:将多个订单更新批量处理,减少锁竞争。
一致性和持久化
- 写前日志(Write-Ahead Logging):所有更改先记录日志,然后应用到内存中的订单簿。
- 检查点(Checkpoint):定期将完整的订单簿状态持久化到磁盘。
- 复制(Replication):维护多个订单簿副本,确保高可用性。
高频交易支持
高频交易(HFT)对交易引擎提出了极高的性能要求。支持高频交易不仅需要优化交易引擎本身,还需要考虑整个交易环境。
低延迟架构
- 硬件优化:
- 使用高性能硬件,如FPGA或专用ASIC。
- 采用内存数据库,减少I/O延迟。
- 网络优化:
- 使用专线或超低延迟网络。
- 实施直连(Direct Market Access, DMA)或托管服务。
- 软件优化:
- 使用低延迟编程语言(如C++)和优化的数据结构。
- 实现无锁算法,减少线程同步开销。
实际案例研究:芝加哥商品交易所(CME)的交易引擎
CME是世界上最大的金融衍生品交易所之一,其交易引擎Globex是业界标杆。
关键特性:
- 超低延迟:订单处理延迟低至40微秒。
- 高吞吐量:峰值可处理每秒数百万笔订单。
- 多样化的订单类型:支持复杂的条件单和算法单。
- 先进的风控:实时风险管理和多层次熔断机制。
- 全球化基础设施:多个数据中心全球分布,支持跨市场交易。
性能基准:
- 平均订单延迟:52微秒(从接收到确认)
- 每秒峰值消息处理量:超过1200万条
- 日均订单量:约2600万笔
- 系统可用性:99.999%("五个9")
这些数据展示了顶级交易所的交易引擎性能,为其他交易所提供了参考标准。
交易引擎的可扩展性设计
随着交易量的增长,交易引擎的可扩展性设计变得至关重要。以下是一些关键策略:
分片(Sharding)
将订单簿按照不同的交易对分割到多个服务器上,每个服务器负责处理特定的交易对。
优势:
- 横向扩展能力:可以通过增加服务器来支持更多交易对。
- 隔离性:单个交易对的问题不会影响其他交易对。
挑战:
- 跨分片交易:处理涉及多个交易对的复杂订单。
- 数据一致性:确保跨分片的数据一致性。
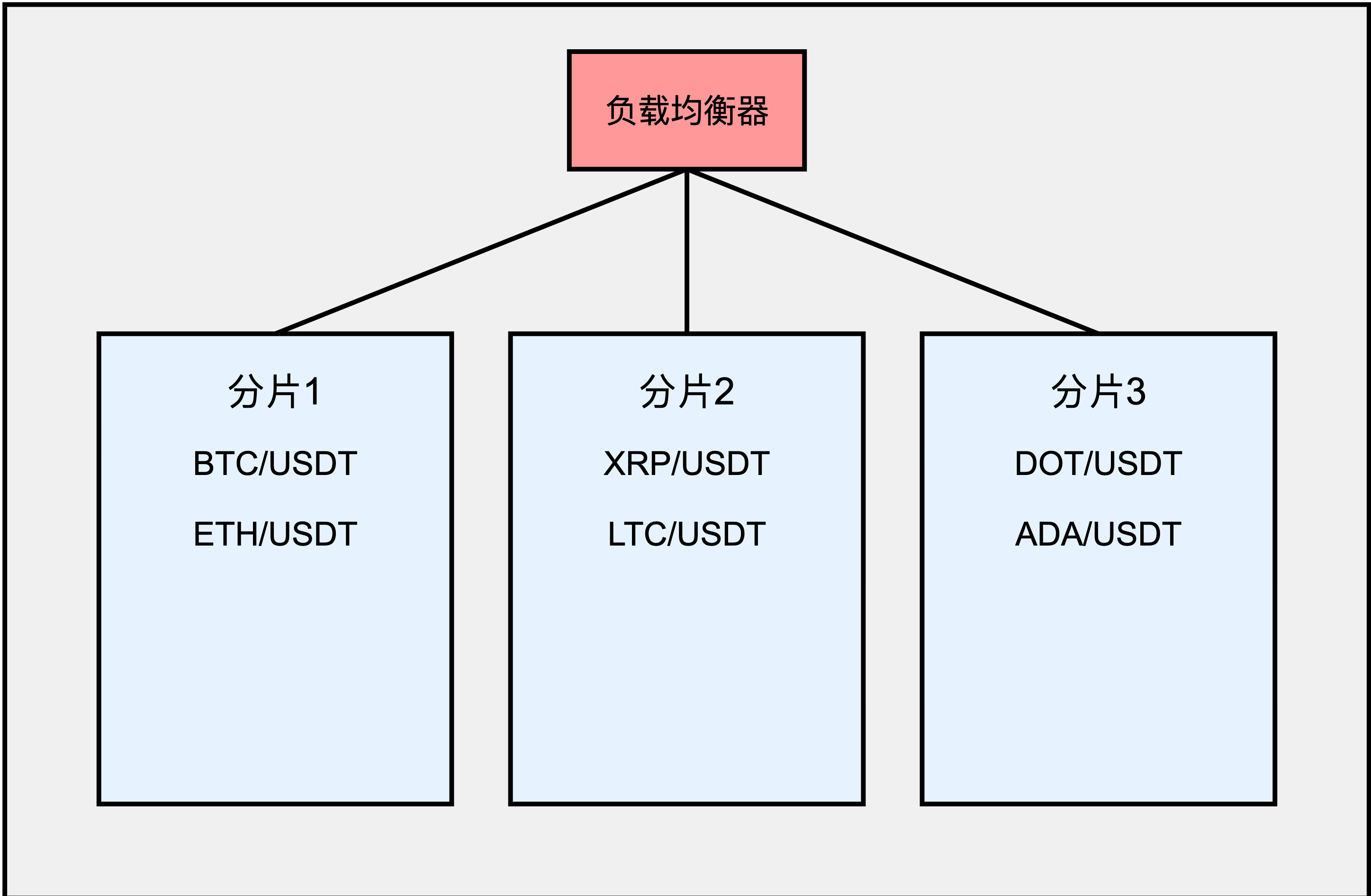
这个图展示了如何将不同的交易对分配到不同的分片上,通过负载均衡器来分发请求。
异步处理
将非核心操作(如通知、日志记录)从主要交易路径中分离出来,异步处理。
实现方式:
- 使用消息队列(如Kafka)存储事件。
- 部署专门的工作者(Workers)处理这些异步任务。
优势:
- 减少主交易路径的延迟。
- 提高系统的整体吞吐量。
多级缓存
实现多级缓存策略,减少对核心交易引擎的直接访问。
典型架构:
- L1缓存:应用服务器本地缓存,存储热点数据。
- L2缓存:分布式缓存(如Redis),存储较大范围的数据。
- L3存储:持久化存储,如数据库。
缓存策略:
- 写透(Write-through):同时更新缓存和存储。
- 写回(Write-back):先更新缓存,异步更新存储。
- 缓存失效(Cache invalidation):及时清除或更新过期数据。
故障恢复和一致性保证
在高频交易环境中,系统的可靠性和数据一致性至关重要。
故障恢复机制
- 快照(Snapshot):定期保存系统状态快照。
- 事务日志(Transaction log):记录所有导致状态变化的事件。
- 检查点(Checkpoint):标记已持久化的日志位置。
恢复流程:
- 加载最近的快照。
- 重放快照之后的事务日志。
- 重建内存中的订单簿和系统状态。
一致性保证
- 原子性(Atomicity):订单处理要么完全成功,要么完全失败。
- 一致性(Consistency):所有节点看到的订单簿状态应该一致。
- 隔离性(Isolation):并发订单的处理不应相互影响。
- 持久性(Durability):已确认的交易不会丢失。
实现策略:
- 使用分布式事务协议(如两阶段提交)确保跨节点操作的一致性。
- 实现版本控制机制,检测和解决数据冲突。
- 采用最终一致性模型,允许短暂的不一致状态,但确保最终一致。
监控和警报系统
有效的监控和警报系统对于维护交易引擎的健康运行至关重要。
关键指标(KPIs)
- 延迟(Latency):订单处理的端到端延迟。
- 吞吐量(Throughput):每秒处理的订单数。
- 错误率(Error rate):失败订单的百分比。
- 系统资源利用率:CPU、内存、网络带宽使用情况。
- 订单簿深度:各价格级别的流动性。
监控工具
- 分布式追踪系统(如Jaeger、Zipkin):跟踪请求在系统中的完整路径。
- 时序数据库(如Prometheus):存储和查询时间序列指标数据。
- 可视化工具(如Grafana):创建直观的仪表板,实时展示系统状态。
警报策略
- 多级警报:根据问题的严重程度设置不同级别的警报。
- 智能阈值:使用机器学习算法动态调整警报阈值。
- 自动化响应:对某些警报实现自动化响应,如自动扩展资源。
总结
交易引擎是合约交易所的核心,其设计和实现直接影响整个系统的性能、可靠性和公平性。通过支持多样化的订单类型、实现高效的撮合算法、优化订单簿管理、支持高频交易,并考虑可扩展性、故障恢复和监控等方面,可以构建一个强大而灵活的交易引擎。
关键要点:
- 多样化的订单类型支持灵活的交易策略。
- 高效的撮合算法确保公平和快速的交易执行。
- 优化的订单簿管理是实现低延迟交易的基础。
- 高频交易支持需要从硬件到软件的全面优化。
- 可扩展性设计确保系统能够应对不断增长的交易量。
- 故障恢复和一致性保证机制确保系统的可靠性。
- 全面的监控和警报系统帮助维护系统的健康运行。
通过不断优化这些方面,交易所可以建立一个高性能、可靠和公平的交易环境,在竞争激烈的市场中保持竞争力。
