React 18 四:Suspense 与异步渲染

在前面的文章中,我们深入探讨了 React 18 的 Concurrent Mode 及其实现原理。作为 Concurrent Mode 的重要组成部分,Suspense 是一种用于处理异步数据加载的新机制,它允许组件在渲染过程中 "暂停" 渲染,直到异步数据加载完成。本文将从 Suspense 的使用方法、最佳实践、工作原理以及异步渲染的错误处理等方面,结合 React 18 的源码进行详细解读。
Suspense 的使用方法
Suspense 的使用方法非常简单,只需将异步组件包裹在 <Suspense> 组件中,并提供一个 fallback 属性即可。当异步组件处于 "暂停" 状态时,Suspense 会渲染 fallback 属性指定的内容,通常是一个 Loading 界面或者占位符。
下面是一个简单的 Suspense 使用示例:
import { Suspense } from 'react';
import AsyncComponent from './AsyncComponent';
function MyComponent() {
return (
<Suspense fallback={<div>Loading...</div>}>
<AsyncComponent />
</Suspense>
);
}
在上面的例子中,AsyncComponent 是一个异步组件,它可能在渲染过程中需要等待异步数据的加载。通过将 AsyncComponent 包裹在 <Suspense> 中,并提供一个 fallback 属性,我们可以在异步数据加载完成之前,显示一个 Loading 界面。
Suspense 的最佳实践
为了更好地使用 Suspense,我们可以遵循以下最佳实践:
- 使用
React.lazy和动态import来定义异步组件,这样可以实现代码分割和按需加载。
const AsyncComponent = React.lazy(() => import('./AsyncComponent'));
- 在 Suspense 中提供一个具有良好用户体验的
fallback界面,如 Loading 状态、骨架屏等。 - 合理划分异步组件的粒度,避免将所有组件都包裹在一个大的 Suspense 中,以提高性能和用户体验。
- 对于数据请求,使用
react-query、swr等成熟的数据请求库,它们与 Suspense 有很好的集成性。 - 使用
<SuspenseList>组件来协调多个 Suspense 组件的显示顺序和加载状态。
下面是一个使用 React.lazy、react-query 和 <SuspenseList> 的示例:
import { Suspense, SuspenseList } from 'react';
import { useQuery } from 'react-query';
const AsyncComponent1 = React.lazy(() => import('./AsyncComponent1'));
const AsyncComponent2 = React.lazy(() => import('./AsyncComponent2'));
function MyComponent() {
const { data: data1 } = useQuery('data1', fetchData1);
const { data: data2 } = useQuery('data2', fetchData2);
return (
<SuspenseList revealOrder="forwards">
<Suspense fallback={<div>Loading 1...</div>}>
<AsyncComponent1 data={data1} />
</Suspense>
<Suspense fallback={<div>Loading 2...</div>}>
<AsyncComponent2 data={data2} />
</Suspense>
</SuspenseList>
);
}
在上面的例子中,我们使用 React.lazy 定义了两个异步组件,使用 react-query 来管理异步数据请求,并使用 <SuspenseList> 来协调两个 Suspense 组件的显示顺序。
Suspense 的工作原理
Suspense 的工作原理与 React 18 的 Concurrent Mode 密切相关。在 Concurrent Mode 下,React 可以在渲染过程中中断当前的渲染工作,转而处理更高优先级的任务,如用户交互。这为 Suspense 的实现提供了基础。
下面是 Suspense 工作原理的简化流程图:
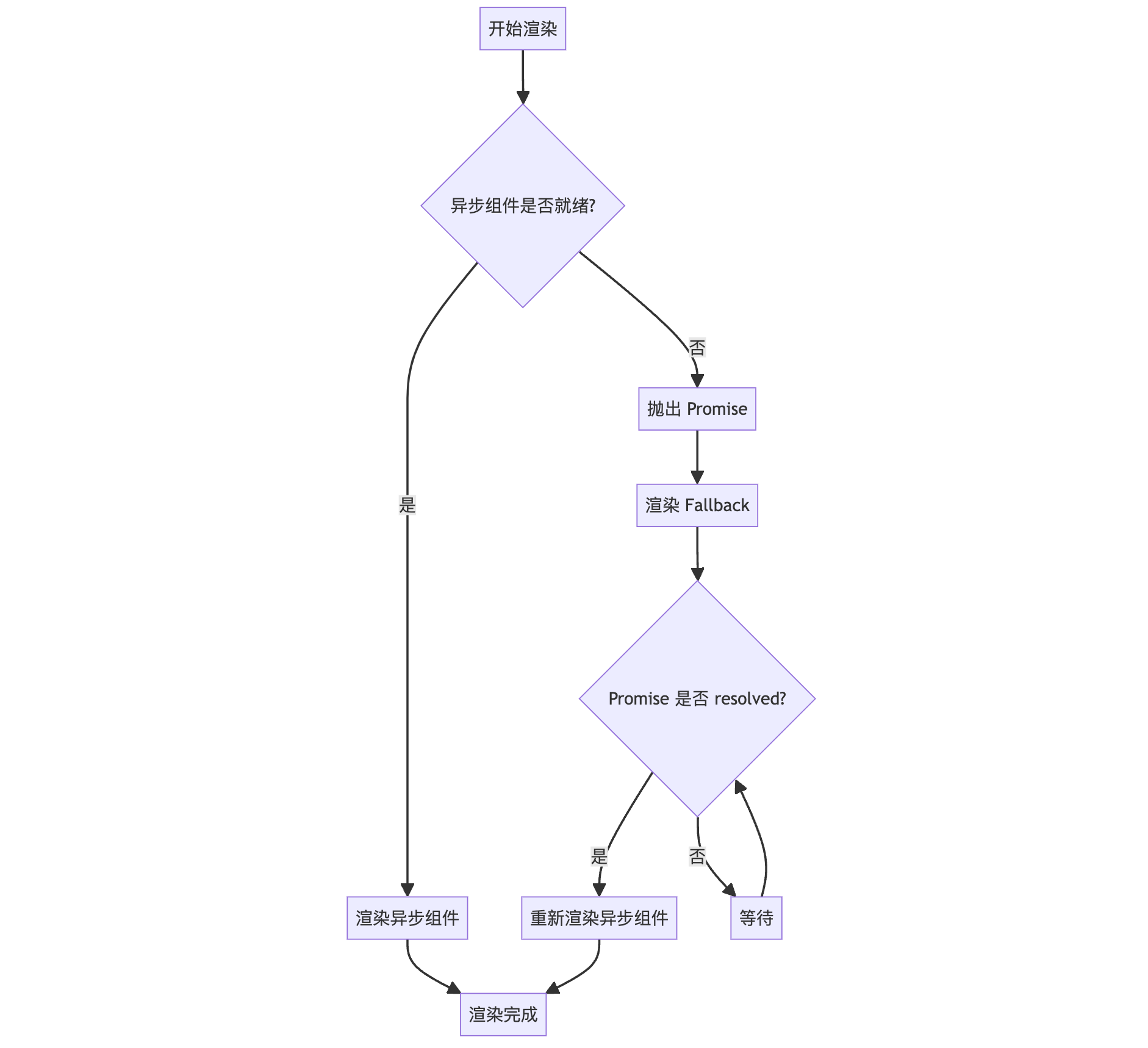
当 React 在渲染过程中遇到一个异步组件时,会先检查该组件是否已经就绪 (即异步数据是否已经加载完成)。如果组件已经就绪,则直接渲染该组件;如果组件尚未就绪,则会抛出一个 Promise,并渲染 Suspense 的 fallback 内容。
当异步组件的数据加载完成后,之前抛出的 Promise 会被 resolved。此时,React 会重新尝试渲染异步组件,由于数据已经就绪,组件可以直接渲染。
在源码中,Suspense 的实现主要涉及以下几个关键函数和概念:
throwException(packages/react-reconciler/src/ReactFiberThrow.js):在渲染过程中抛出 Promise,用于暂停当前的渲染工作。updateSuspenseComponent(packages/react-reconciler/src/ReactFiberBeginWork.js):处理 Suspense 组件的更新,包括处理异步组件的就绪状态、渲染fallback等。completeWork(packages/react-reconciler/src/ReactFiberCompleteWork.js):在完成异步组件的渲染后,重新尝试渲染 Suspense 组件。workInProgress:表示当前正在进行的 Fiber 节点,用于追踪组件的渲染进度。renderExpirationTime:表示当前的渲染过期时间,用于判断异步组件是否已经就绪。
通过这些函数和概念的配合,React 实现了 Suspense 的异步渲染和数据加载功能。
异步渲染的错误处理
在使用 Suspense 进行异步渲染时,我们还需要考虑异步操作可能出现的错误情况,并提供相应的错误处理机制。
在 React 18 中,我们可以使用 <ErrorBoundary> 组件来捕获和处理异步渲染过程中的错误。<ErrorBoundary> 可以包裹在 <Suspense> 的外层,用于捕获 Suspense 内部组件抛出的错误。
下面是一个使用 <ErrorBoundary> 处理异步渲染错误的示例:
import { Suspense } from 'react';
import ErrorBoundary from './ErrorBoundary';
import AsyncComponent from './AsyncComponent';
function MyComponent() {
return (
<ErrorBoundary fallback={<div>Error occurred!</div>}>
<Suspense fallback={<div>Loading...</div>}>
<AsyncComponent />
</Suspense>
</ErrorBoundary>
);
}
在上面的例子中,我们使用 <ErrorBoundary> 包裹了 <Suspense> 组件,并提供了一个 fallback 属性,用于在错误发生时显示错误信息。
当 <AsyncComponent> 在渲染过程中抛出错误时,错误会被 <ErrorBoundary> 捕获,并渲染 fallback 属性指定的内容。这样,我们就可以优雅地处理异步渲染过程中的错误,提供更好的用户体验。
在源码中,异步渲染的错误处理主要涉及以下函数:
throwException(packages/react-reconciler/src/ReactFiberThrow.js):在渲染过程中抛出错误,用于中断当前的渲染工作。handleError(packages/react-reconciler/src/ReactFiberWorkLoop.js):处理渲染过程中抛出的错误,包括调用<ErrorBoundary>的componentDidCatch方法。
通过这些函数的配合,React 实现了异步渲染过程中的错误处理机制。
