TheGraph 一: 架构解析

The Graph 的整体架构图:
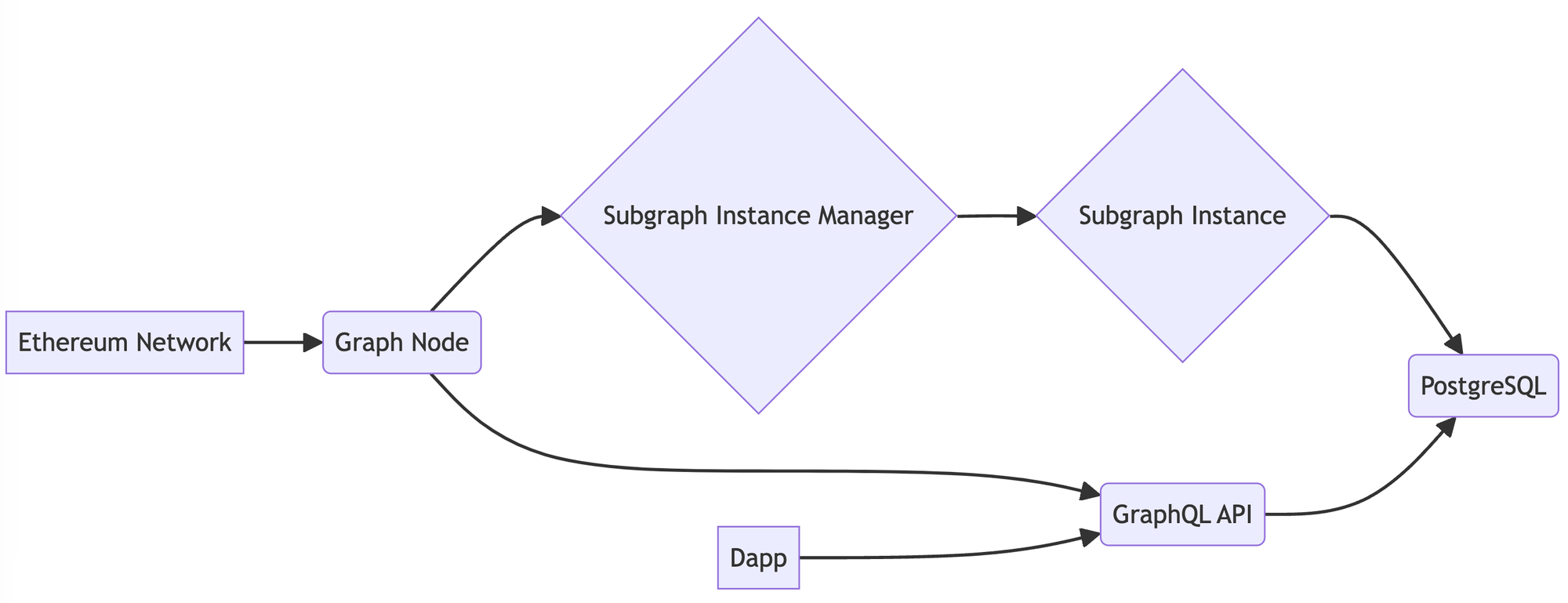
The Graph 与 SubGraph 交互流程的时序图:
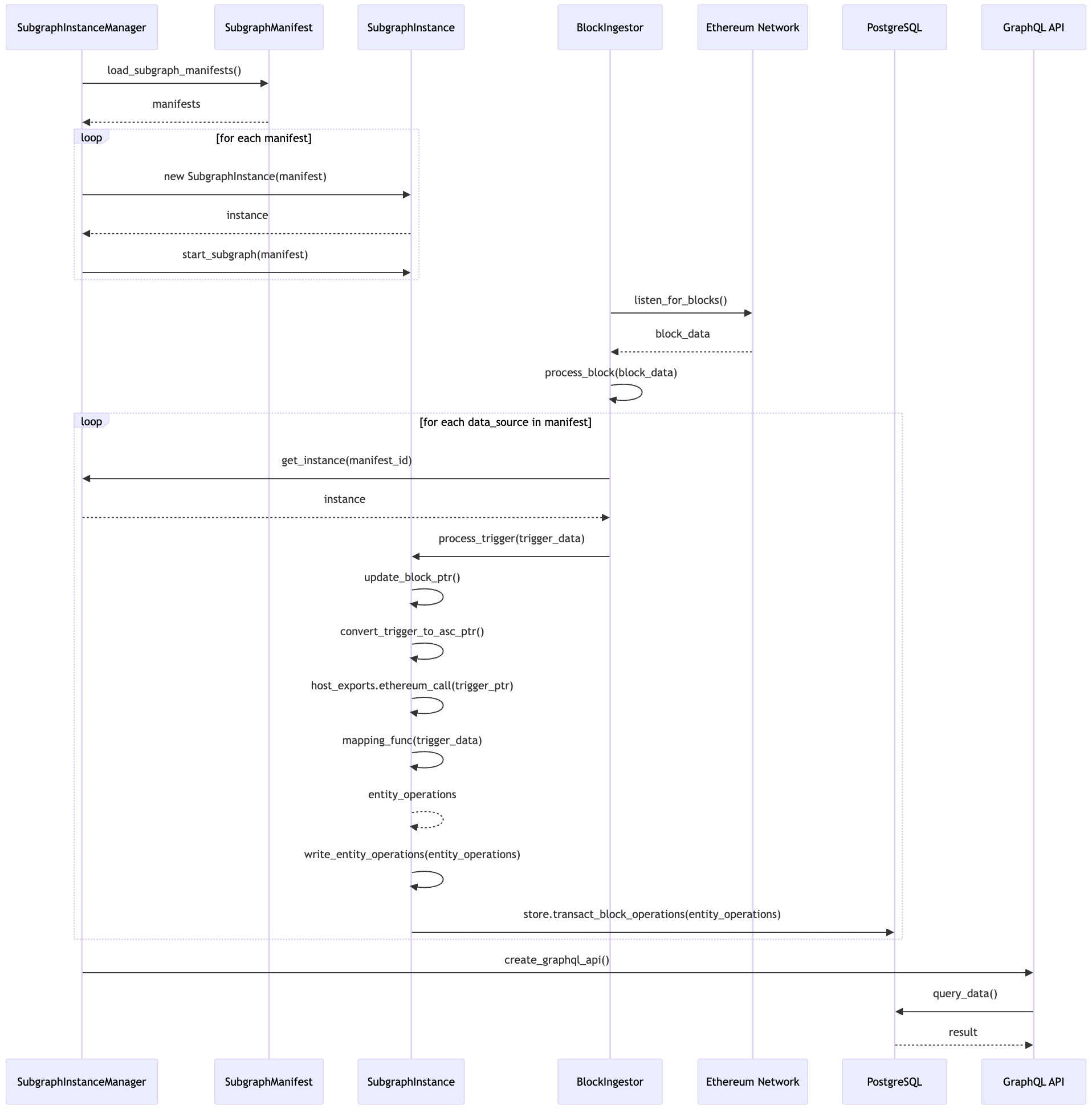
接下来,我们结合架构图和时序图,对其中的关键节点和源码进行详细解释,并说明 subgraph 中的关键定义数据是如何串联整个流程的。
一、Subgraph Instance Manager 加载和管理 Subgraph Instance
load_subgraph_manifests()方法加载所有已部署的 subgraph 配置信息。
fn load_subgraph_manifests(&self) -> Result<Vec<SubgraphManifest>, Error> {
// ...
let mut manifests = vec![];
for entry in fs::read_dir(&self.subgraph_manifest_dir)? {
// ...
let manifest = yaml::from_reader(file).map_err(|e| {
format_err!("invalid subgraph manifest in {:?}: {}", path, e)
})?;
manifests.push(manifest);
}
Ok(manifests)
}
这里的 SubgraphManifest 就是 subgraph 的关键定义数据之一,它包含了 subgraph 的 schema、数据源、mapping 函数等信息。
create_instance()方法根据SubgraphManifest创建SubgraphInstance。
fn create_instance(
&self,
manifest: SubgraphManifest,
host_metrics: Arc<HostMetrics>,
) -> Result<SubgraphInstance, Error> {
// ...
let required_capabilities = manifest.required_ethereum_capabilities();
let network_name = manifest.network_name();
let instance = SubgraphInstance::from_manifest(
&manifest,
self.host_builder.clone(),
host_metrics.cheap_clone(),
self.link_resolver.cheap_clone(),
required_capabilities,
)?;
Ok(instance)
}
可以看到,SubgraphInstance 是根据 SubgraphManifest 创建的,SubgraphManifest 中定义的信息会被传递到 SubgraphInstance 中。
二、BlockIngestor 获取区块数据并分发给 SubgraphInstance
process_block()方法根据SubgraphManifest中定义的 DataSource,将区块数据拆分为一个或多个TriggerData。
fn process_block(&mut self, block_ptr: BlockPtr) -> Result<bool, Error> {
// ...
for data_source in self.ctx.manifest.data_sources.iter() {
let data_source_name = data_source.name.as_str();
let triggers = data_source.triggers_in_block(&block_ptr)?;
// ...
for trigger in triggers {
// ...
self.process_data_trigger(trigger, block_ptr)?;
// ...
}
}
Ok(true)
}
这里的 data_source 就是 subgraph 的另一个关键定义数据,它定义了如何从区块链上获取数据,以及如何将原始数据转换为 TriggerData。
process_trigger()方法将TriggerData发送给对应的SubgraphInstance。
pub fn process_trigger(
&self,
logger: &Logger,
manifest_id: &SubgraphDeploymentId,
trigger: &TriggerData,
state: BlockState,
proof_of_indexing: SharedProofOfIndexing,
causality_region: &str,
) -> Result<BlockState, MappingError> {
let instance = self.instances.read().unwrap().get(manifest_id).ok_or_else(|| {
format_err!("no instance for subgraph `{}` when processing trigger", manifest_id)
})?;
instance.process_trigger(logger, trigger, state, proof_of_indexing, causality_region)
}
这里的 manifest_id 就是用来标识和匹配 SubgraphInstance 的,确保 TriggerData 被发送到正确的 SubgraphInstance。
三、SubgraphInstance 处理 TriggerData 并将结果写入数据库
process_trigger()方法处理TriggerData,调用 mapping 函数生成EntityOperation。
pub fn process_trigger(
&mut self,
logger: &Logger,
trigger: &TriggerData,
mut state: BlockState,
proof_of_indexing: SharedProofOfIndexing,
causality_region: &str,
) -> Result<BlockState, MappingError> {
// ...
let trigger = Arc::new(trigger.to_asc_ptr());
let result = self.ctx.host_exports.ethereum_call(
logger.clone(),
block_ptr,
trigger,
state.deref_mut(),
proof_of_indexing,
causality_region,
);
// ...
}
这里的 mapping 函数就是 subgraph 的第三个关键定义数据,它定义了如何将 TriggerData 转换为 EntityOperation,也就是如何将区块链数据转换为 The Graph 的数据模型。
write_entity_operations()方法将EntityOperation写入本地的 PostgreSQL 数据库。
fn write_entity_operations(
&self,
logger: &Logger,
entity_operations: Vec<EntityOperation>,
) -> Result<(), StoreError> {
// ...
let entity_count = self.store.transact_block_operations(
entity_operations,
None,
&self.subgraph_id,
block_ptr,
store_event,
)?;
// ...
}
这里的 entity_operations 就是 mapping 函数的输出,代表了对数据库的写入操作。store 则是 The Graph 的本地数据库组件,负责将数据持久化存储。
四、GraphQL API 提供数据查询服务
GraphQL API 会根据 subgraph 的 schema 定义生成相应的查询接口,供 Dapp 调用。当收到查询请求时,会将请求转换为相应的数据库查询,从 PostgreSQL 中获取数据并返回。
这里的 schema 定义就是 subgraph 的第四个关键定义数据,它定义了 The Graph 数据模型的结构,以及暴露给 Dapp 的 GraphQL 查询接口。
综上所述,subgraph 的四个关键定义数据:
SubgraphManifest: 定义了 subgraph 的基本信息,如 schema、数据源、mapping 函数等。DataSource: 定义了如何从区块链获取数据,以及如何将原始数据转换为TriggerData。- Mapping 函数: 定义了如何将
TriggerData转换为EntityOperation,即如何将区块链数据转换为 The Graph 的数据模型。 - Schema: 定义了 The Graph 数据模型的结构,以及暴露给 Dapp 的 GraphQL 查询接口。
这四个部分串联了整个 The Graph 的工作流程,从区块链数据的获取、到数据的转换和存储、再到数据的查询和服务,形成了一个完整的数据处理管道。
通过这种方式,The Graph 实现了区块链数据的高效索引和查询,为 Dapp 提供了一个方便、快捷、灵活的数据服务层。Dapp 开发者可以通过定义 subgraph,将复杂的区块链数据映射为简单的 GraphQL 模型,大大降低了开发复杂度和门槛。
同时,这种架构也具有很好的可扩展性和可维护性。新的 Dapp 可以方便地接入 The Graph 网络,只需定义自己的 subgraph 即可。而 The Graph 网络可以通过增加节点来横向扩展,支持更大的数据量和查询吞吐。
希望通过这个结合架构图和关键源码的分析,能够帮助你更全面、更深入地理解 The Graph 的工作原理,以及 subgraph 在其中扮演的重要角色。如果还有任何问题或建议,欢迎随时交流探讨。
